Plex and Youtube Video
Before the summer, I’ve bought a new NAS, a Synology model to replace the old HP Microserver who served well for years.
If you want to go directly to the setup, you may skip cutscene.
With this new toy, I wanted to experiment the Plex Media Server, a popular solution for home media server. It took me almost two months, mistreated two AMD Ryzen 7 CPUs, but I’ve ripped my entire DVD and Blu-ray library to fill this media server.
One thing that was missing was the few Youtube video makers I enjoy. I’ve been a long time user of an Invidious instance, but the instability and the slowness were pissing me. And recently, Youtube and other Big Tech compagnies blocked FDN’s network. So their Invidious instance doesn’t work anymore… My choice to do my own simple setup wasn’t a bad one.
So here is the idea : by using yt-dlp, a Youtube video downloader tool, and very powerful for various streaming services, and a custom basic Python script, I pool the RSS feeds of the various channel I follow and locally download the content.
You may think it's illegal, but so far, not in France. An exception exists in the Author's right allowing people to make copies for private usage in exchange of a tax on various digital storage support, such as smartphones, external hard drives, raw DVD, etc., collected by a dedicated organisation that use the money to compensate the authors. As long as you don't break any DRM, which is forbidden by the LCEN law and keep the private usage… private, there's no reason for this method to be illegal. Other European countries have the same kind of law, check in yours.
But you won’t support the artists like this !
- If the French Youtubers are not payed by the private copy commission, they just ask to change the law and extend the perimeter. Copie France is greedy, they won’t dislike the idea I suppose.
- I send money to the one I enjoy.
Subscribe to channel’s RSS
At the beginning, I used Invidious’ ability to generate RSS feeds for a Youtube channel. But after the FDN’s instance being unavailable, I’ve remembered that, surprisingly, Youtube still have RSS feeds.
So, I’ve saved the feeds in a file named channels.txt.
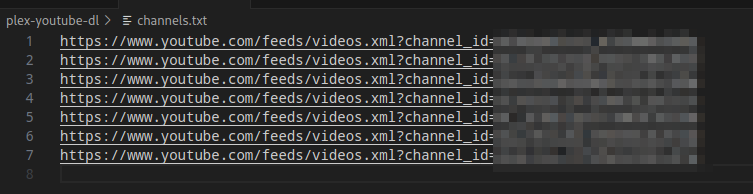
The URL construction is quite simple, it’s the same base URL with the channel’s ID.
Use a script to pool videos
I won’t put this script on GitHub, I don’t want a stupid bot to take it down. So here is the Python code :
import feedparser
import subprocess
import os
# Read a list of RSS feeds for Youtube and download the video to a dedicated folder
# using a naming convention
# Released under MIT license
# Copyright 2024 Seb - https://zedas.fr
# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
# The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
# THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
files_path = '/path/to/plex/youtube/folder'
channels_file = 'channels.txt'
if not os.path.exists(channels_file):
print("channels.txt is missing. Please create a file named channels.txt at the same place and put the feeds URL inside")
exit()
# Read the already downloaded videos file and put them into a variable
urls_file = 'urls.txt'
downloaded_urls = set()
if os.path.exists(urls_file):
with open(urls_file, 'r') as f:
downloaded_urls = set(line.strip() for line in f)
# Read the channels file and generated a list
urls_rss_feed = []
with open(channels_file, 'r') as f:
for line in f:
url = line.strip()
urls_rss_feed.append(url)
# Loop over the channels
for rss_feed_url in urls_rss_feed:
print(f"Processing RSS feed : {rss_feed_url}")
rss_feed = feedparser.parse(rss_feed_url)
entries = rss_feed.entries
# Read each RSS entry in the feed
for entry in entries:
title = entry.title
url = entry.link
author = entry.author
date = entry.published
url_youtube = url
# Check if the video haas already been downloaded
if url in downloaded_urls:
print(f"Video '{title}' already downloaded.")
continue
# print(url)
# Download the video in a dedicated path and naming it like this :
# Youtuber/youtuber - title - video_id
command = f'yt-dlp -o "{files_path}/%(uploader)s/%(uploader)s - %(title)s - %(id)s.%(ext)s" --sponsorblock-mark all --embed-metadata --parse-metadata "%(uploader|)s:%(meta_artist)s" "{url_youtube}"'
result = subprocess.run(command, shell=True)
# Add the URL to the history file
if result.returncode == 0:
with open(urls_file, 'a') as f:
f.write(url + '\n')
else:
print("error,cannot register url to history")
In a requirements.txt file, you should put :
yt-dlp
feedparser
And to run it, I use a good old bash script :
#!/usr/bin/env bash
# Proposed under MIT license
# Copyright 2024 Seb - https://zedas.fr
# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
# The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
# THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
if [ -d venv ]; then
rm -rf venv
fi
virtualenv venv
source venv/bin/activate
pip install -r requirements.txt
python /path/to/plex-ytdlp.py
It’s quite basic, so you can enhance it if you want.
And I’ve crontabed it every hour.
00 * * * * bash /path/to/plex-ytdlp.sh
Organize the Plex library
While learning to use Plex, I’ve learned it’s also a pain in the ass for the libraries. That’s a reason I’ve always hated media servers software, they never works the way I expect. Anyway, I’ve finally found a way that was suitable for me.
So, first, I’ve created a Plex Library judiciously named “Youtube”, using the “Other videos” kind.
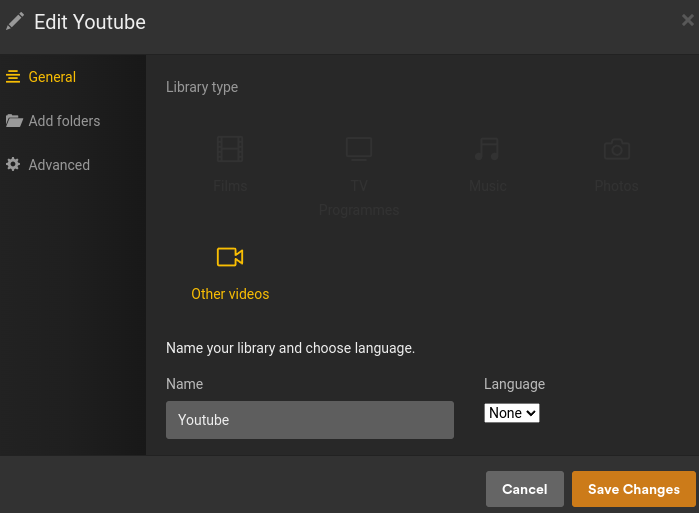
And set the “youtube” root folder from my NAS.
But, the videos will be a mess, you may think. Yes, they are, everything in the same library, a mess ! But I didn’t want to create a library per Youtuber. So I’ve used a nice Plex feature : Smart Collections.
That’s why I’ve used a naming convention for the videos, the Smart Collection uses filters to populate itself.
In the Youtube library, on the right, click on “Create a Smart collection”
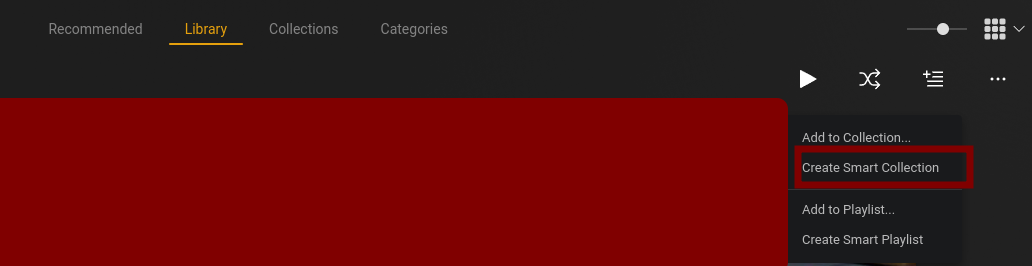
Select the “Title” criteria, “begins with” and type the name of the Youtuber, followed by a space and a dash. Such as : Somebody - . As every videos are named like this, the collection will populate itself.
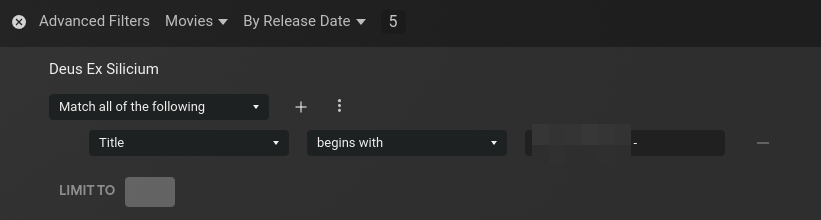
Save it and do the same for each subscription.
If you add a feed, the good news is yt-dlp will create the folder automatically. However, you’ll still have to create the collection manually. I suppose it’s possible using Plex’s API, but I haven’t check this side, I don’t have this requirement.
Et voilà !
In a next article, I’ll explain how I’ve made a Discord bot to add a specific video on the Plex server.