Use a CI/CD workflow to maintain a book content

This may sound a little incongruous if for you the Continous Integration / Continuous Delivery patterns are for software development, but yes, you can maintain a book with the same principles.
Recently, I’ve compiled the Linux Explained articles into an e-book. The idea was germinating in my head while writing the articles and I was wondering if I could maintaining the text using the CI/CD patterns.
Actually : yes, it’s possible.
Actually again, it’s not a revolution, a lot of documentations and writings are maintained in the same way.
So I’ve tried to figure out by myself how to achieve that. A traditional CI/CD pipeline is a workflow that will checkout code from a source code repository, compile it using the language-related compiler or packager, use Quality Gates to ensure the quality of the product, produce an artifact, and publish it on a shelf for further installation. And if you add a second “D” to CI/CD:D you will add the “Deployment” step to the continuity.
For a book, the code is the text, the “programming” language is Markdown in my case, the “compiler” is Pandoc, and the artifact is an EPUB e-book. Let’s do it step by step.
About Markdown
Markdown is a markup language created in 2004 by John Gruber and Aaron Swartz designed to be lightweight and human readable. It uses a very simple syntax to format a text using headlines, links, references, text styling, and so on. This blog articles are written using this markup language actually.
# Heading
## Sub-heading
Some text. *Some text in italic*, **some text in bold**
| A | table | With | columns |
| - | ----- | ---- | ------- |
| a | b | c | d |
[A link](https://to-the-past)
Markdown has, in my opinion, two big advantages : it’s very simple to write and read, and nowadays pretty common and almost standardized. Almost because initially, Markdown was a specification with ambiguous parts and its implementations diverged until the standard CommonMark got established, unambiguous this time. However, there are still some custom implementations, or flavors, maintained by several actors. For example, GitHub maintains its “GitHub-flavored Markdown” version since 2009. BitBucket, Diaspora, OpenstreetMap, Reddit, etc, use their own variants.
Markdown also became a pretty common writing language for note takings with several text editor using it for text formatting with online preview (in the text, or in a separated area), dynamic screenshot insertion, etc. In my case, I use Zettlr to write on this blog, and the book Linux Explained was reshaped with Ghostwriter, both Markdown text editors.
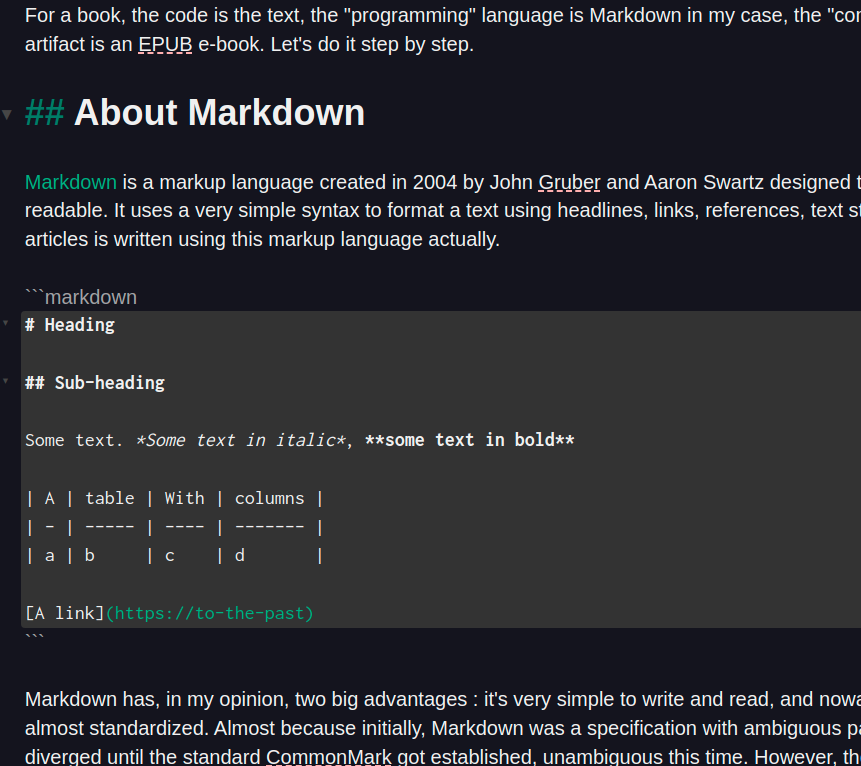
Zettlr using Markdown.
Why two editors ? Actually, Zettlr is great for its project management aspect using workspaces with files and a navigator, for my blog it’s perfect. On its side, Ghostwriter is single file (you edit one file at time and can open several instances), but it is able to export the content with various documents converters, such as Pandoc. And for the book, I needed Pandoc.
About Pandoc
Pandoc is a universal document converter created by John MacFarlane. It can convert files from a markup language to another. It’s a very clever tool since you don’t really have to tell it the input format and you just need to specify the output. I needed this tool to convert the markdown files into the epub book. For the anecdote, MacFarlane was among the people who launched the CommonMark initiative.
Pandoc is a command line tool that takes the input files as parameters and the expected output with some settings. In my workflow, I produce the book with the following command :
pandoc -o linux-explained.epub \
--resource-path=.:book $(ls book/00-*.md book/01-*.md book/02-*.md) \
--standalone
Here is the explanation :
-o: the output filename--resource-path: Some context for Pandoc to help it to find the medias attached to the book (the images). The syntaxe is :[relative-path]:[subfolder]:[another-folder].--standalone: An option to produce the expected header and footer in the HTML files in EPUB
In the first versions, I’ve also used the --toc argument to generate the table of contents. But it broke the render on the e-book reader.
In return, a file named linux-explained.epub is produced.
About EPUB
EPUB is an e-book file format, a technical standard published by the international Digital Publishing Forum superseding the older Open eBook standard. This format is widely used and accepted by the e-book readers.
Basically, an EPUB book is a collection of XHTML files including the styling and images packaged into a zip archive using the .epub extension.
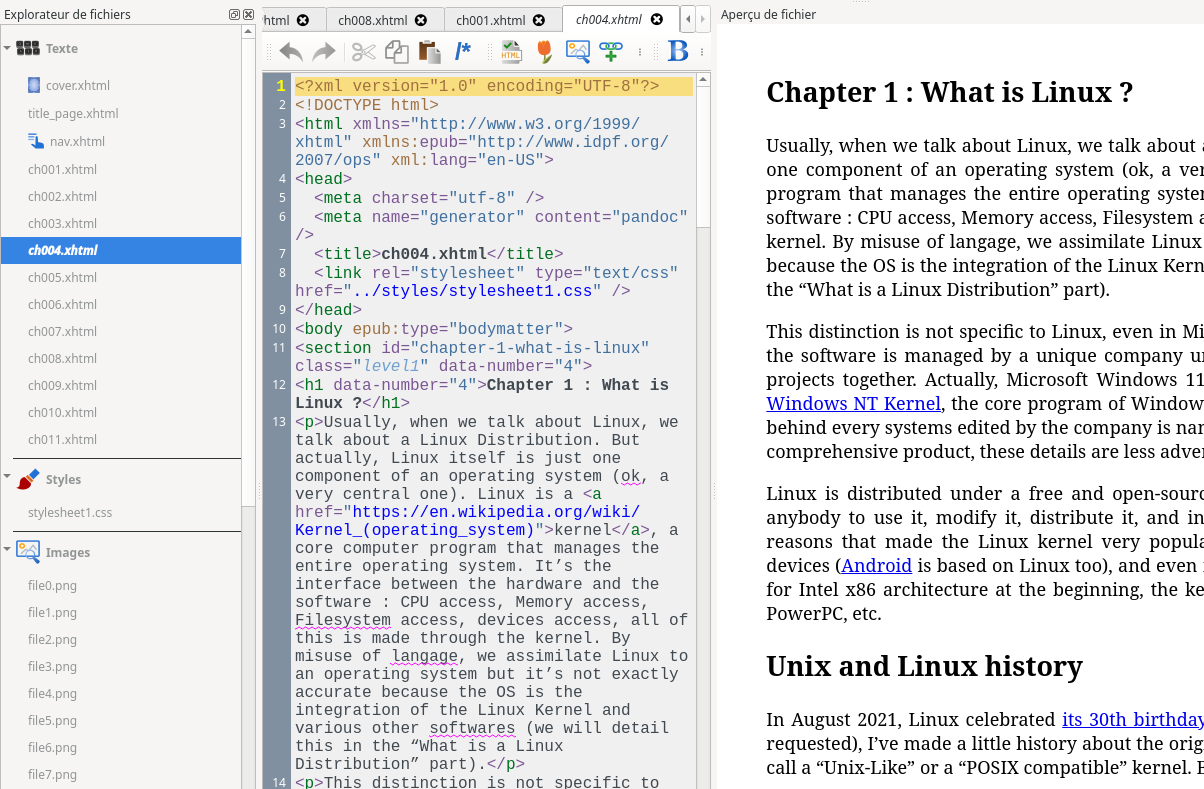
The content of the Linux Explained e-book version published with EPUB, opened by the e-book editor of Calibre, a digital library software.
Thanks to Pandoc, the Markdown files are converted into the XHTML structure for the EPUB format and compiled into the archive. Now you can transfer the book to your favorite reader.
The book rendered in my e-reader.
To make sure my epub output is correct, I’ve used the EPUBCheck tool provided by the W3C.
$ java -jar /opt/epubcheck-5.0.0/epubcheck.jar ~/Downloads/linux-explained.epub
Validating using EPUB version 3.3 rules.
No errors or warnings detected.
Messages: 0 fatals / 0 errors / 0 warnings / 0 infos
EPUBCheck completed
# Yeay !
The repository structure
So, let’s dive into the topic and see how I’ve organized the Git repository.
.
├── book
│ ├── 00-01-title-page.md
│ ├── 01-02-chapter-2.md
(...)
│ ├── diagrams
│ │ ├── boot-sequence.excalidraw
│ │ ├── filesystem.excalidraw
│ │ ├── graphical-shell-startup.excalidraw
│ │ ├── group-managed-accesses.excalidraw
(...)
│ ├── img
│ │ ├── boot-sequence.png
│ │ ├── cc-by-sa.png
│ │ ├── Debian_Unstable_GRUB2.png
│ │ ├── filesystem.png
│ │ ├── find-exec.png
│ │ ├── find-xargs-24.png
│ │ ├── firefox-proxy.png
(...)
│ └── linux-explained.md
├── .github
│ ├── dependabot.yml
│ ├── FUNDING.yml
│ └── workflows
│ ├── ci.yml
│ ├── delete-prereleases.yml
│ ├── dependabot.yml
│ └── release.yml
├── .gitignore
├── CHANGELOG.md
├── CODEOWNERS
├── CONTRIBUTE.md
├── LICENSE.md
├── README.md
└── version_file.json
In the first approach, I’ve wanted to maintain the whole book into a single file. That’s the linux-explained.md that remain there (it has been eventually deleted). But with some thoughts maintaining a big text file was difficult since the GitHub pull request diff interface won’t render it and the file will be too big. I’ve decided to split it into several parts.
First, since the repository’s root contains various explanation and technical files, I’ve decided to put the book’s sources into a dedicated directory : book. The root basically contains the README, license, contribution, and technical items.
Inside the book directory I have the .md files composing the book, and two sub-folders : the img folder contains the diagrams rendered files and the diagrams folder contains the sources of the images made using Excalidraw.
Since EPUB is a normalized format, I’ve decided to split the introduction parts and chapters into dedicated files. To ensure the files will be taken in the proper order by Pandoc, I’ve used the following convention :
00-0x-something/mdfor each front matters files01-0x-chapter-x.mdfor each chapters files02-0x-something.mdfor each back matters files
The back matters file are the bibliography part, quoting every reference used to write the book.
The build workflow
Now let’s explore the CI/CD part. Since the book’s sources are hosted on GitHub, I’ve used GitHub Actions’ workflow to generate the epub file. The main workflow is called release.yml and do the following tasks :
- Writing the
epubfile from the sources - Generating the change log
- Pushing the GitHub release with the
epubasset and the change log
name: Release epub
on:
workflow_dispatch:
workflow_call:
jobs:
publish:
runs-on: ubuntu-latest
permissions:
contents: write
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Fetch files in workspace
id: book-files
run: echo BOOK_FILES=$(ls book/00-*.md book/01-*.md book/02-*.md) >> $GITHUB_OUTPUT
- name: Write epub
uses: docker://pandoc/core:2.14
with:
args: "-o linux-explained.epub --resource-path=.:book ${{ steps.book-files.outputs.BOOK_FILES }} --standalone"
- name: Produce release note
uses: TriPSs/conventional-changelog-action@v3
id: changelog
with:
github-token: ${{ secrets.github_token }}
version-file: './version_file.json'
- name: Publish release
uses: softprops/action-gh-release@v1
if: ${{ steps.changelog.outputs.tag }}
with:
body: ${{ steps.changelog.outputs.clean_changelog }}
tag_name: ${{ steps.changelog.outputs.tag }}
files: |
linux-explained.epub
Since the Pandoc step is ran from a Docker Action, I’ve had to first generate the list of files composing the book before executing the tool. This is the purpose of the Shell task and its output. Then, I use two common and appreciated community Actions to make the change log and upload the release.
The repository is expected to respect the Conventional Commits or the change log generation may fail. If the change log produces no output, the release step will be ignored.
If you’re familiar with GitHub Actions’ syntax you may have noticed the two triggers :
workflow_dispatch: For a manual executionworkflow_call: Make this workflow reusable for the repository
Another workflow file name ci.yml is used to trigger the release.yml depending of a pull request or a push action.
name: Pull Request
on:
pull_request:
paths-ignore:
- '.github/**'
push:
branches:
- main
paths-ignore:
- '.github/**'
jobs:
pullrequest:
permissions:
contents: write
if: ${{ github.actor != 'dependabot[bot]' }}
uses: Wivik/linux-explained/.github/workflows/release.yml@main
The workflow will ignore every changes made in the .github directory since it’s not a book content source. Also, we ignore if the actor is Dependabot because it’s sole purpose is to update the project’s technical dependencies (mainly Actions versions). We trigger the reusable workflow following this.
Some possible enhancement ?
This first workflow requires some tuning to be better, here is a list of what I could enhance.
Integrate the EPUBCheck tool
The EPUBCheck tool could be a nice quality gate for our CI/CD workflow. A next step would be to add it in the workflow and abort it if the verification fails.
Ensure the Pull Request / Integration workflow work
Currently, the Pull request workflow has not yet been tested, only the integration. The PR workflow should not publish or tag, only checking if the quality gates are passed and try to build the book.
Generate the Excalidraw diagrams
Instead of storing the PNG outputs, the Excalidraw diagrams should be generated during the book’s production. It would reduce the storing of binary files, something that Git is not really made for. But in the other hand, recreating them each time may not be efficient too.
Create a PDF file too
Because EPUB is not an all-purpose format, the PDF is more common and Pandoc can produce them too.
